
Initial Thoughts On Cypress
Cypress has been around for a few years at the time of me writing this post, and it’s become really popular. I’ve noticed that it’s becoming a staple in various job postings and stacks, so after working with Selenium for my web automation needs, I gave Cypress a shot on my own time.
I watched two courses about Cypress on Pluralsight and was generally impressed with what I saw. I decided to put together a relatively simple SPA to use Cypress with. It’s a chmod calculator based off of the one Simon Sheppard made for ss64.com’s chmod page.
You can find the demo application I made for this here, and the GitHub repo is here.
My demo website
The website I created for this article is an Angular clientside app that will calculate the numbers to use with chmod for file permissions in Linux. The UI elements of the app include:
- Several static
<p>elements and a static<h1>element - An input field
- A
<p>element that will change when the content of the input field changes (a dynamic field) - A table containing 9 buttons that can change the value within the input box AND their color to signal that they’re toggled on or off
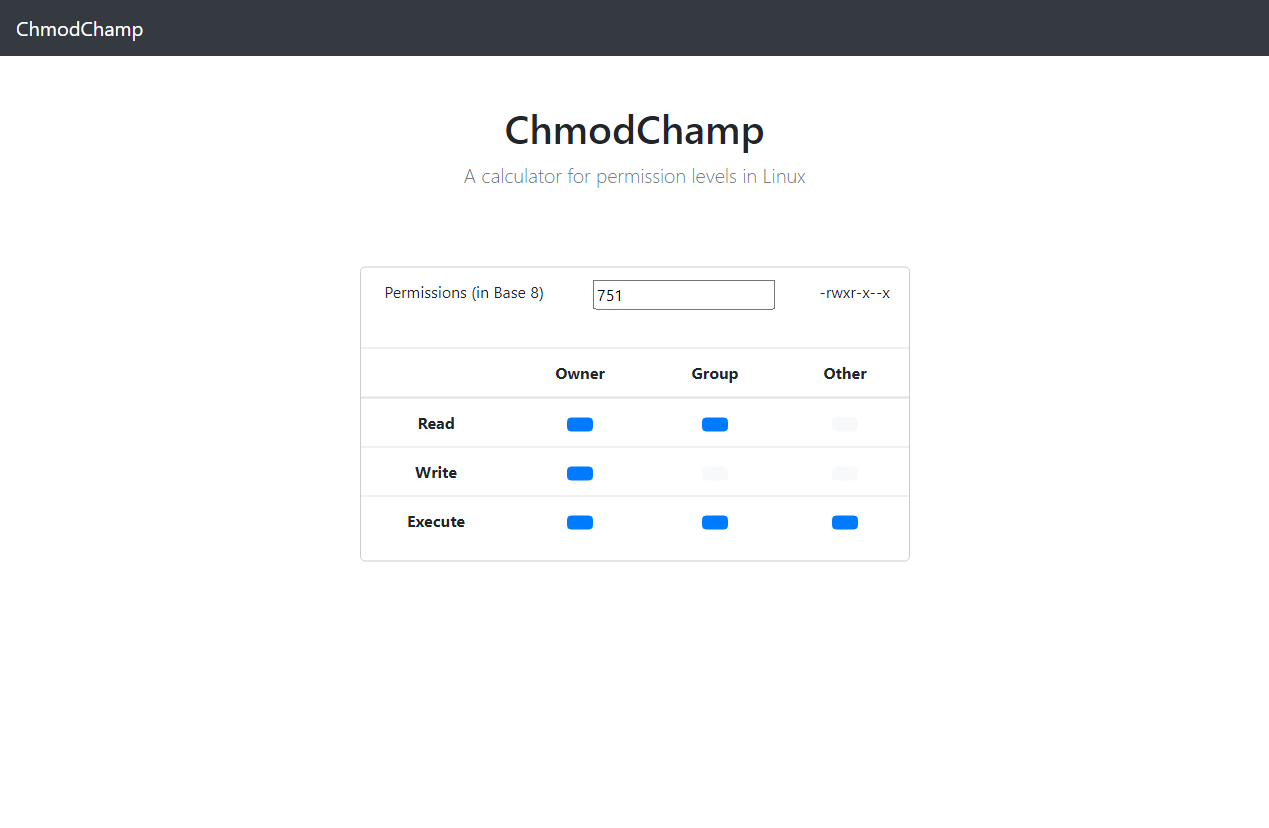
Way more than a simple “hello world” application but nothing that will push the cognitive bank in regards to writing tests and figuring out functionality and edge cases.
Adding Cypress and taking it all in
The JavaScript ecosystem with npm is quite nice: all I needed to do to add Cypress to my project was npm install cypress. I could have (and probably should for serious/actual projects) added the --save-dev flag to that installation line to add it as a dev dependency rather than a hard dependency needed to run the app.
Once npm finished all the heavy lifting, there was a nice and shiny cypress folder in my project with some folders, one of them including some sample tests. They were decently legible for JavaScript and had enough comments, so it wasn’t hard to leverage their content for my own trials.
One thing I wasn’t crazy about off the bat is how the examples in the Cypress project’s GitHub repo aren’t as clear as the Cypress official documentation. I learned more about the basics and somewhat advanced usage of Cypress by reading the docs page for certain features and modules than I did looking at the Cypress examples repo.
Next up was looking at the Cypress Test Runner, where all the great user-friendly features of Cypress were. A user can click any one test suite (.spec) file to run it and once the suite is done running, the test window will remain open and that’s where Cypress really begins to shine. Once everything is done, users can open up tests within the suite and hover over each step to follow the path of execution.
When I hovered over the step that was typing numbers into the input box of my webapp, the webapp was displayed to the right of the tests. If I left my cursor over that input step, it would toggle back and forth between what the app looked like before the input and what it looked like after the input. This is where I went “alright, Cypress is awesome".
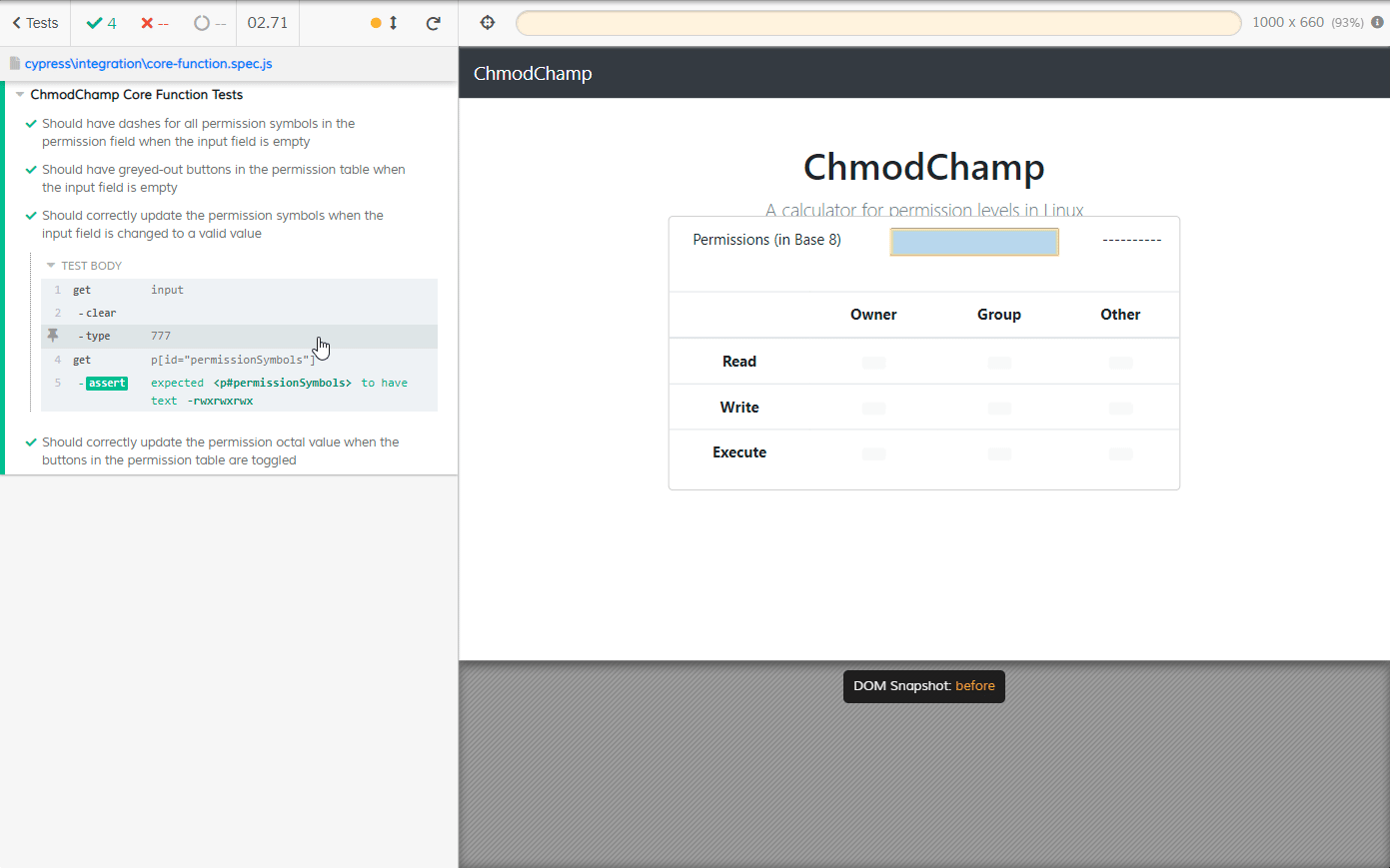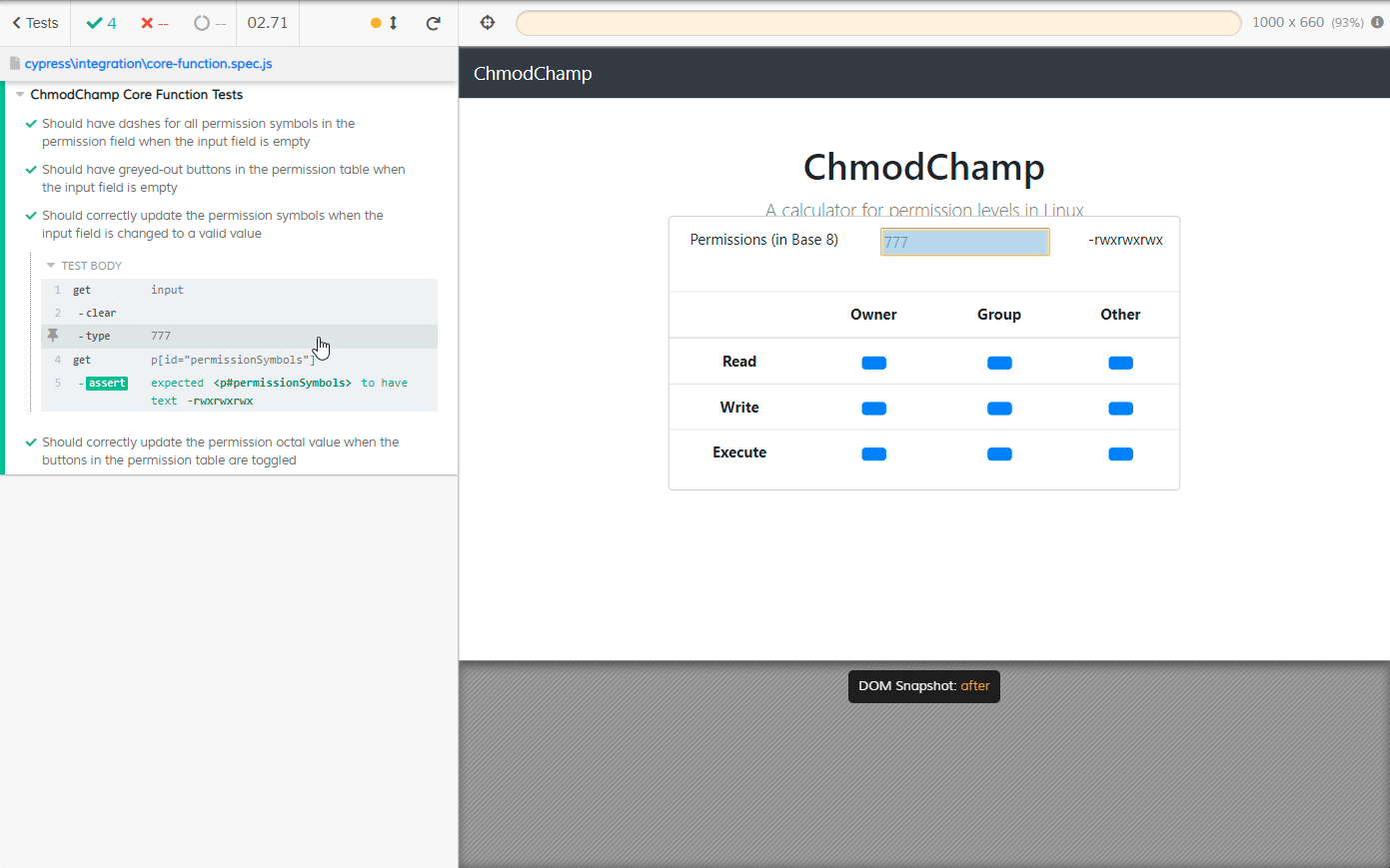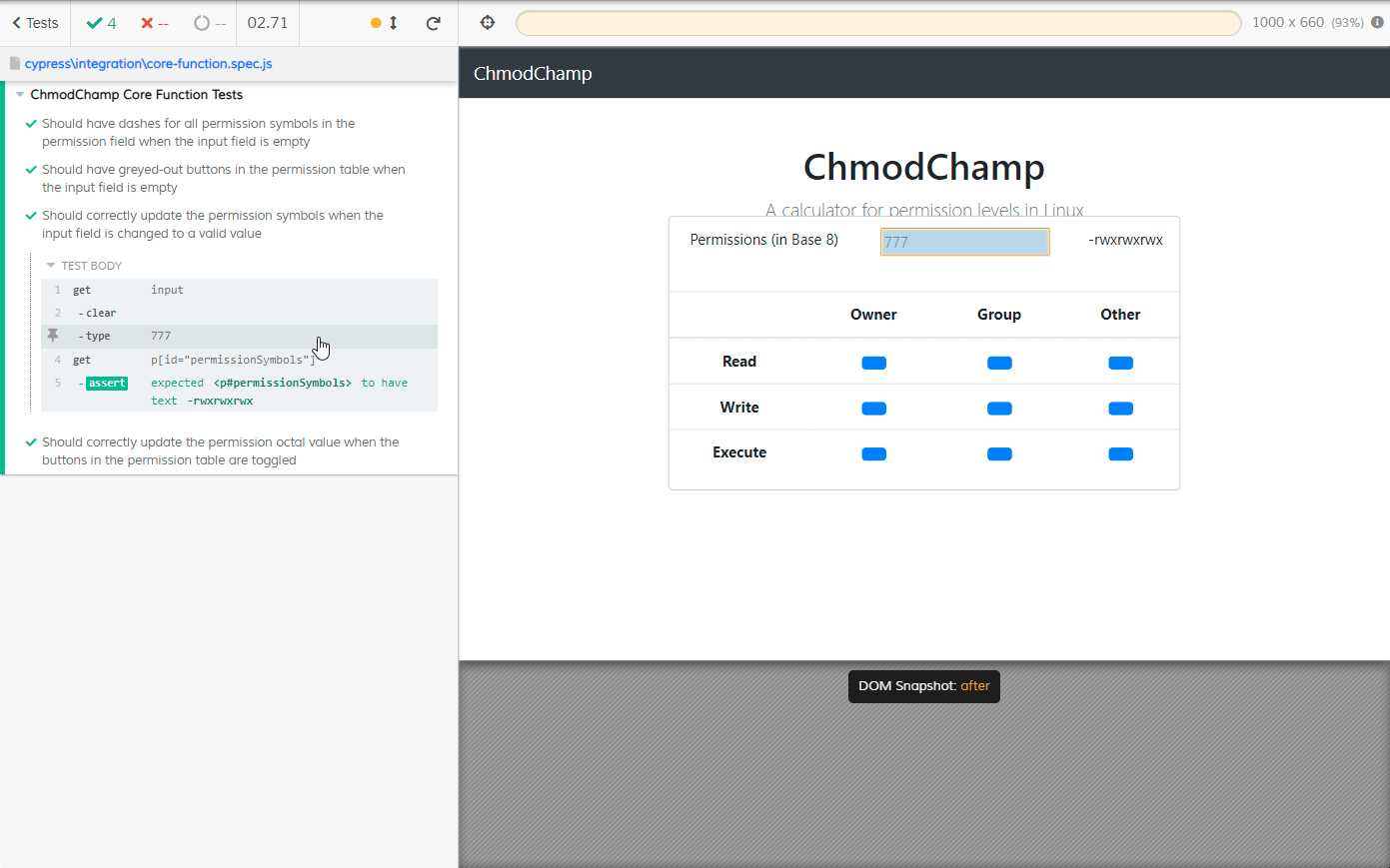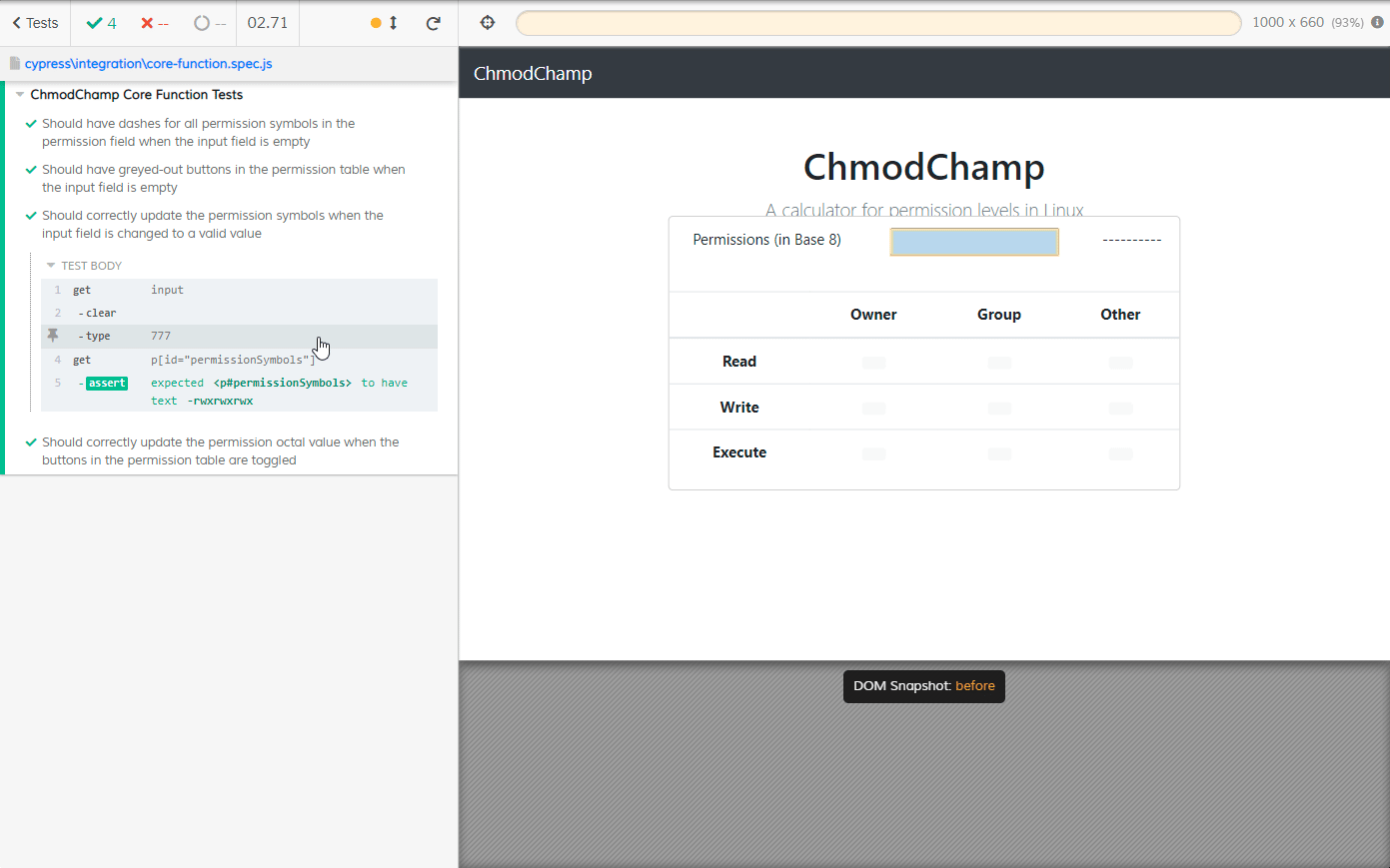
One thing that was a huge pain in Selenium and desktop automation with things like Ranorex and TestComplete was not having access to previous state of the SUT - that is, it was difficult to keep track of what the application looked like before an action was performed and what it looked like after in a reliable manner. Attempting to keep track of this for desktop applications using TestComplete or Ranorex relied on copious amounts of screenshots, which were difficult to follow when viewing a log.
With pictures, I’d need to click back and forth a few times for my eyes to catch what was changing, be it things we wanted to see changed or things we weren’t expecting to change. With Cypress? Just hover, and the demo page in the runner will flip between snapshots of the DOM before and after the action! It’s even better than just having an animated .gif or video because we’re actually looking at the webapp in a webpage. That means I can open the dev tools and hover over elements myself to see what’s going on!
However, I needed some tests of my own.
What was good about Cypress
As I mentioned previously, I had some idea of what tests and test suites would look like because I had watched some Pluralsight courses and looked around the docs before I got started. I broke down my tests into two suites: smoke-tests.spec.js that would check if my webapp was displaying as it should in a default state, and core-function.spec.js that would test the functionality of my webapp.
It was easy to apply whatever style of application testing I wanted to use
I like to use NUnit for my unit tests in C#, which relies on the “assert” pattern outlined in Test Driven Development: when a unit of work does something, we should assert that the result is what we expect it to be. However, for end-to-end/UI tests, I personally like to think more in a Behavior Driven Development manner: given that the SUT is in a certain state, when a user does something with our system, then our system should be in some other state.
Cypress supports both methodologies. Due to my personal preference, I decided to use the BDD approach and leverage Cypress’s should function. Even though my application was so small and I was writing JavaScript, I was still pleasantly surprised at how concise and legible I could make my test cases.
Fixtures made it really easy to have data-driven testing
One thing that was difficult during one of my previous stints in SDET/QA Automation was that having data-driven tests was easy for some of our applications and difficult for others. There wasn’t really a standard approach to data-driven development because our systems had different test requirements but all required data of some kind, and we leaned heavily on database queries before testing and even calling external “helper” libraries during testing to get even the simplest of data.
Cypress makes data driven testing extraordinarily easy with fixtures. I can populate a JSON file with some data I’d like to use frequently during testing, such as default values and element IDs, and then use the fixture function to create an object that will contain all of the default values I would be using during testing. It’s set up before any tests run in a suite using the before function, and available!
I realize that this is a genuinely simple demonstration, most QA systems have it or something like it in place, and should be a design goal for almost all automated systems. However, the fact that it’s JSON files within my project directory is a huge win in productivity: it works with source control, all of the data types provided by standard JSON are available, and I can add a JSON file on the fly while designing new cases. All of that feels like just the tip of the iceberg, where I can imagine generating JSON files from a database or API call with a separate utility during the entire CI process.
To provide some context about why the implementation of fixtures feels amazing: at the aforementioned SDET position I was employed at, our test framework was leveraging an Excel sheet for loading its data. It required its own set of classes for parsing that was contained within one of our “helper” .dlls, then our tests would have to make an instance of that Excel reader class to load the file. Unless we had third-party software or someone wrote their own version control in-house, it was a genuine struggle to track the changes for our data set. It was incredibly easy to make a mistake and have to fiddle around with git just to get back to working normally. In conjunction, having the entirely separate classes dedicated to reading the data workbook meant we had more code to read and know about.
With fixtures, it’s all contained within the framework. I can read data from a fixture in a specific test, or before a set of tests I can stuff the fixture’s data into an object so that all of the subsequent tests can leverage the data from that object. It’s all in JavaScript (or TypeScript, which I’ll discuss later!) and it can all be contained within the Cypress directory associated with the project! There’s less need to maintain external code or software for reading data, it uses a common data format, and it all plays nicely with version control (git, SVN, etc.).
TypeScript is an option
Another thing that I like a lot is that there isn’t any difficulty in going “hmmm…. I would actually like to use TypeScript for my implementation of Cypress”. Just a few additions to configuration files, and I can immediately get type safety for my automated tests in addition to all of the pleasant language features and syntactic sugar that TypeScript grants. Normal JavaScript is fine and works just as well in regards to implementing new tests and features, but TypeScript removes a lot of the uncertainty when developing and running tests. No more thoughts of “Wait a minute… this test is passing but the object we’re getting back is Any? What are we checking here exactly?”
At a minimum, having things like intellisense and compiler-time errors to catch things ahead of time is a huge win for TypeScript. As someone who values readability and documentation (both in and outside of code), being able to express what types we as developers should expect from some function to accept as arguments and receive as results is just another “W” for the win column. I consider these things critical when dealing with a large codebase that will cover a lot of ground; in this case, an automation suite that will more than likely leverage page object models or data transfer objects.
Mark Erikson has a great blogpost about the benefits of TypeScript, his learning process in introducing it into projects, and the benefits and tradeoffs he’s encountered. Give it a read here.
Things I wasn’t a huge fan of
There are several things that I took note of for my demo project that kind of rubbed me the wrong way. I did some external research on what other users were saying about Cypress in terms of its negatives, but these are sourced from my experiences.
JavaScript, anonymous functions
I’m going to get straight to the point: I think JavaScript is a mess of a language visually. There are too many books out there on writing “eloquent” JavaScript and I think that’s a problem with the language itself. The problem I have with JavaScript as it’s written when used with Cypress is that test suites are declared with a function called describe. This function takes a string and a function as arguments, and then all of the tests associated with this suite become sub-functions. With the global cy object, we can get elements and chain other functions to get calls like then and within, which also accept functions as arguments.
What I noticed is that raw/simple tests were prone to becoming densely packed together:
it('Should correctly update the permission octal value when the buttons in the permission table are toggled', () => {
cy.fixture('elementIds').then((ids) => {
cy.get('table[id="permissionToggleTable"').within(() => {
let buttonArr = ids.buttons.filter(b => b.includes("group"));
for (let i = 0; i < buttonArr.length; i++) {
cy.get(`button[id=${buttonArr[i]}]`).click();
}
});
});
cy.get('input').should('have.value', '707');
});
This is a really simple test, probably simpler than is sufficient to explain my concerns, but it demonstrates some of them. I can write external functions to supplement this so that commands are more descriptive, but this is a common enough JavaScript pattern that I’m loathe to see what this might look like if someone needs to pump out a test fast. What I liked about using Selenium with C# bindings and the desktop automation frameworks I’ve worked with was that I was able to give tests adequately descriptive names, and the tests would contain method/function names that adequately described what was happening at each step.
I can’t recall what Ranorex’s structure looked like perfectly, but I valued being able to have code that read like:
public static void RanorexProprietaryRunMethod_ThatIncludedTestName()
{
var testData = RetrieveStringsForElementValidation();
NavigateToFeature();
var onScreenElement = CustomMethodToGetElementAsObject();
AssertThatElementIsCorrectLeveragingRanorexAssertFeatures(onScreenElement, testData);
}
The names describe what’s going on and their implementations can be navigated to in order to follow execution. This is just moving code elsewhere, but a clear top-down flow of execution is easier to achieve when writing like this. Depending on the approach of the individual or team using Cypress, I’m more likely to be reading raw implementation details within the test.
This complaint can probably be alleviated with good design leveraging POMs and external functions, but Cypress itself seems to be against the concept of POMs and favors writing explicit functions for test units. Based on seeing other JavaScript automation codebases and Cypress’s philosophy, I think seeing multiple nested anonymous functions is going to be a reasonable expectation.
“Black box” wait implementation
Cypress handles almost all “waiting” logic for you; that is, any code where you’d like to wait for an element or data to be available on your front end. To me, this is a boon if the front end project doesn’t have anything that’s incredibly custom-tailored. A CMS could be perfect in this case where the content being retrieved is going to be consistent and in small doses, or it could be a highly technical CMS that tracks a lot of data at once and you want to have several conditions met before moving forward. At a previous position, my team and I wrote a lot of different implementations of waiting logic (making it reusable where we could) because the company’s software had to meet several requirements, and our “wait for” methods would reflect this.
While Cypress is open source and I can go look at its code, I’d only have the time to perform that kind of audit if my tasks explicitly required it. I get why Cypress handles all waiting logic for us, but there are definitely times I’d like or need more fine-grained control. I don’t think it’s a massive problem because most websites aren’t going to be as dense or complex per page in contrast to a desktop application, but it stood out.
Cross browser testing is in its infancy
I was somewhat surprised to see that Cypress originally only supported automation on Chrome until very recently. With cross-browser testing being in its infancy, I don’t know how I’d feel about running automation for complex frontend projects using Cypress until more users have gone through some struggles and discoveries. I don’t think this is a dealbreaker since many companies (erroneously) only test with Chrome these days and if the application is straightforward enough, there’s not a lot of risk of something not working on Firefox or Internet Explorer (still hoping that IE goes away completely eventually, we’re almost there).
It’s definitely something I’d keep in the forefront of my mind when suggesting Cypress or thinking about using it for my projects that are more complex. Time will make this less of an issue as it’s a popular demand.
Parting thoughts
I think Cypress is overall a neat tool and there’s a nonzero chance I’ll use it for a future real side project of mine. The pros of Cypress currently outweigh the cons somewhat, but that weight can shift depending on the type of project. Microsoft’s Playwright CLI might be an interesting next look from here.